Your engineering team already relies on linters like ESLint, Prettier, or Rubocop to catch code issues before they reach production.
These tools flag style violations, enforce consistency, and reduce code review time by automating the tedious aspects of quality control, leading to quicker code reviews, consistent output, and a lower mental burden.
Unfortunately, most technical teams don’t apply this same practice to their technical content.
Docs, guides, and tutorials undergo entirely manual reviews, where reviewers spend time flagging missing Oxford commas, inconsistent terminology, and overly long sentences.
If you’re a small content team supporting dozens of engineers or managing contributions from external developers, this manual review process becomes a bottleneck.
Reviewing technical content manually results in slow publishing cycles, inconsistent docs quality, and frustrated contributors.
This is where prose linting comes in.
Prose linting solves these issues by automating style and consistency checks the same way code linters do. It’s a significant part of the Content as Code approach: treating all technical content with the same rigor as code.
Table of Contents
What Is Content as Code?
Content as Code extends the Docs as Code methodology beyond docs to all technical content, meaning guides, tutorials, and blog posts, treating them with the same rigor as software code.
This means writing content in Markdown, storing it in version control, conducting reviews through pull requests, and running automated quality checks as part of your publishing pipeline.
Everything sits in the same repository and follows the same development workflow.
This approach works well for engineering teams because it integrates seamlessly with the tools they use daily. There’s no need to switch to a separate editor or learn a new publishing system. Writing, reviewing, and releasing docs becomes part of the same workflow as writing code.
This methodology provides proper version history for all content, supports collaborative workflows across roles, and supports the addition of automated quality checks as part of the publishing pipeline.
Organizations like Google, Microsoft, GitHub, Datadog, and ContentSquare already use Docs as Code. Extending it to all technical content enables faster growth.
You Grow Faster with Automated Content QA
Ship Content Faster
Automated linting handles the first-pass review for style, terminology, and consistency, so human reviewers can focus on technical accuracy instead of policing syntax.
Authors get feedback immediately in their IDE or when they open a pull request, allowing issues to be corrected before review, shortening review cycles, and increasing merge speed without reducing quality.
At Datadog, a 200:1 developer-to-writer ratio still supports reviewing around 40 docs pull requests per day. In 2023, the team merged over 20,000 pull requests across dozens of products and integrations.
Automated checks made this volume possible by catching repetitive style issues early and reducing the mental load on writers and reviewers without adding headcount.
When a prose linter like Vale runs in CI, it catches most style guide violations even before a human reviewer sees the PR, so reviewers spend less time pointing out minor fixes, and pull requests move through review faster.
Scale Your Contributor Program
External contributors often submit content with inconsistent style and terminology because they haven’t memorized your style guide. Without automated checks, reviewers spend time explaining these standards through manual feedback on every PR.
However, automated prose linting communicates these standards through immediate, actionable feedback, so contributors see and grasp “what good looks like” without reading lengthy style guide documents.
ContentSquare saw measurable growth in engineering contributions after implementing Vale for prose linting.
Engineers reported feeling more confident contributing because they received clear guidance about what to fix. This lowers the barrier to entry for developers who are technical experts first and writers second.
Build Developer Trust
Consistent terminology and style signal professionalism and reliability to your users.
Docs quality directly shapes product trust and adoption, especially with technical audiences who quickly lose confidence when they encounter inconsistent terminology or explanations.
If one page says “authenticate” and another says “log in,” or if the same concept is described in different ways across pages, developers notice.
Automated quality checks prevent these issues before they reach production by enforcing consistency across the entire docs set, which helps you maintain credibility as the product evolves.
Furthermore, automated checks ensure your docs remain current as your products evolve. When docs lag behind releases, developers lose confidence in their accuracy.
Automated checks solve this by allowing teams to ship updates quickly without compromising quality standards. The combination of consistent quality delivered at speed becomes a competitive advantage for developer adoption.
What Vale Does
To implement automated prose linting, most engineering teams start with Vale, an open source prose linter that checks content against style rules.
It runs locally on your machine, inside your IDE, via pre-commit hooks, in pull request checks, or as part of your CI/CD pipeline.
Vale understands the syntax of Markdown, AsciiDoc, and reStructuredText, so it can parse your content correctly and ignore code blocks or other markup.
Alternative prose linters include textlint, proselint, and alex, but Vale is the most common choice among engineering teams.
Basic Setup Steps
- Install Vale via your package manager (Homebrew on macOS, Chocolatey on Windows, or apt/yum on Linux)
- Generate a .vale.ini default configuration file at your project root. You can use existing style packages like Google or Microsoft, or create custom rules.
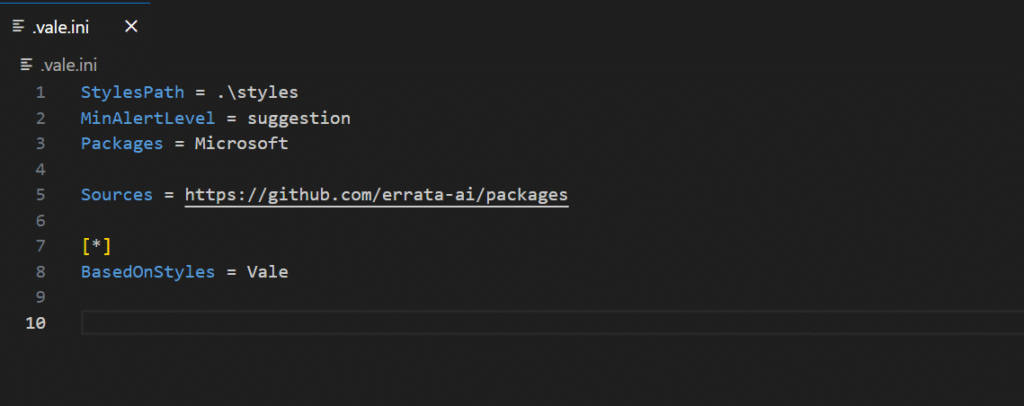
- Run vale sync to download the style package

- Run vale [path/to/content] to lint your files
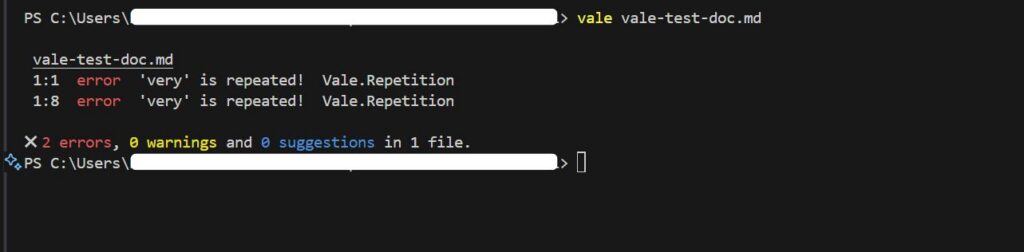
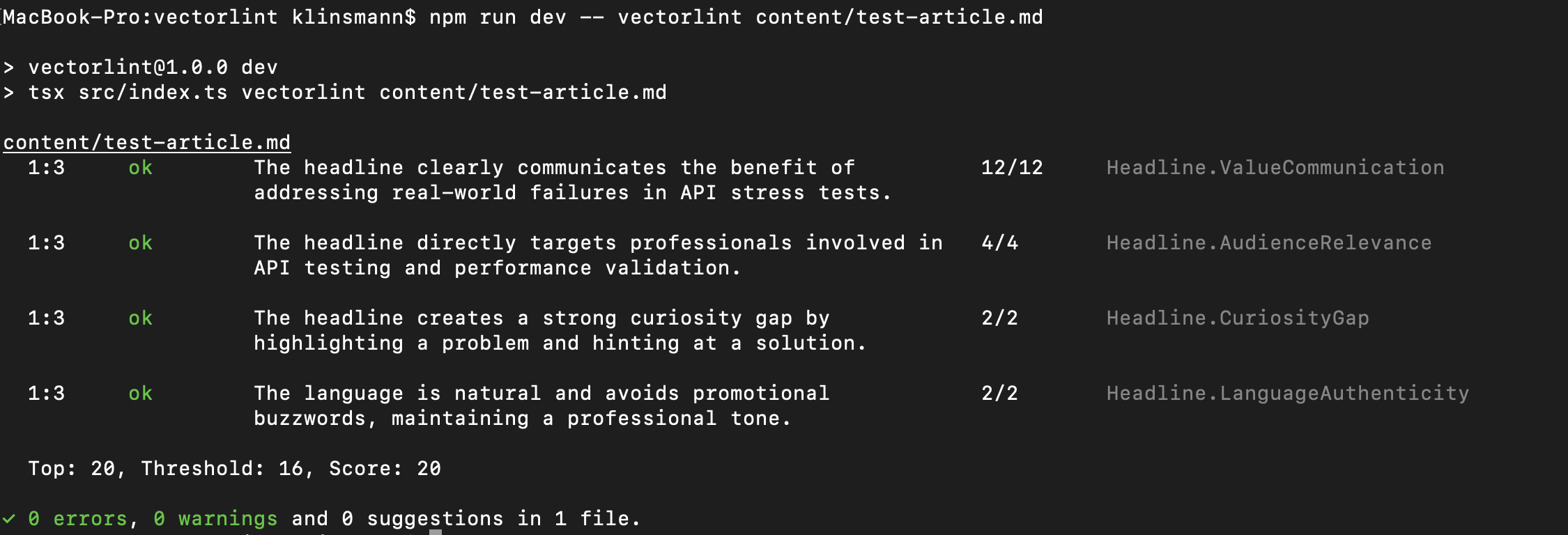
What Automated Feedback Looks Like
Vale flags issues with line numbers and provides suggested fixes for problems like overly long sentences, filler words, inconsistent terminology, and style violations like missing Oxford commas.
This feedback appears whether you run Vale in your terminal, your IDE, or as automated comments on pull requests.
Once you see how Vale flags issues, you’ll be tempted to enable every available rule. Resist that urge.
Start with 5 Rules, Expand Over Time
The Progressive Rollout Approach
Don’t launch with 50 rules; start with 5-10 focused on your biggest pain points. Pilot Vale on one docs set, such as your API reference, getting started guide, or README files.
Gather feedback from your team and iterate on the rules based on what they find helpful or frustrating. Expand coverage gradually as the system proves its value.
Teams that roll out too many rules at once face resistance and overwhelm from contributors. A progressive rollout builds team buy-in and confidence in the system.
You’ll see initial value within weeks, with fewer style inconsistencies flagged during review, and faster merge times. The benefits compound over months as your team internalizes the standards and your rule set matures.
ContentSquare implemented this approach and saw a growth in contributions as engineers became more confident in contributing to docs.
This progressive approach works, but it’s not a “set it and forget it” solution.
You Need Maintenance To Succeed
Setting up prose linting requires an initial time investment for installation and rule tuning.
Some rules will need adjustment based on your specific content type, as what works for API docs may be too strict for tutorial content or technical guides.
Team buy-in matters more than perfect configuration from day one, and the system works best when integrated into your existing workflow.
Expect to refine rules as your team discovers edge cases, add exceptions for product-specific terminology, and occasionally tune thresholds for readability metrics.
The good news is maintenance gets easier over time as your rule set stabilizes and your team adapts to the workflow.
Many engineering teams at companies like Datadog and ContentSquare automate their content quality checks, reporting significant improvements in review speed and output consistency.
The challenge for smaller teams is implementing and maintaining the automation pipeline.
That’s where TinyRocket helps: we implement production-ready prose linting systems tailored to your workflow, so you can focus on building your product, not maintaining docs tooling.