Content engineering, or content operations engineering, has a slightly different definition depending on who you ask.
In enterprise content management, it means applying engineering principles to structure content into reusable modules, manage metadata and taxonomies, and deliver content across channels.
In marketing and search engine optimization (SEO), it means building workflows, automation, and AI to create, update, and distribute content at scale.
For developer tool companies, content engineering is an extension of documentation engineering.
Documentation engineering is the practice of building systems that keep docs aligned as the product evolves. Content engineering extends it to marketing content by building workflows, quality gates, and automation that keep blog posts, tutorials, guides, and launch pages in sync with the product as it ships.
Regardless of how each industry defines it or the tools involved, the common goal is to treat content as a systems problem rather than a series of one-off deliverables.
Content engineering is emerging now because teams want to use AI to gain efficiency and scale content without a proportional increase in effort. AI tools can produce content quickly, but teams have realized that speed without a system leads to inconsistent quality.
This is especially important for developer tool companies as AI increases development velocity.
Why Developer Tools Need Content Engineering
More features shipping faster means more content to produce and maintain, more frequently. For developer tools that pose a risk of content drifting from the product.
Documentation is part of the product, and developers judge your tool by how well your docs help them ship. So when content is out of sync with your product, developer experience degrades.
A stale code sample, a deprecated API reference, or a tutorial that no longer reflects the current UI would cause developers to spend more time verifying your tool instead of building with it.
It also affects how you get surfaced in AI search. AI assistants that read your content use your documentation and marketing pages as a retrieval context. If your docs and marketing pages are factually inconsistent or riddled with terminology inconsistencies, they can surface contradictory product explanations or omit your product altogether.
The good thing is that developer tool companies already use foundational infrastructure such as Git and running CI/CD pipelines, so adopting content engineering practices is a natural extension.
If you’re already practicing Docs as Code, content engineering builds on that foundation.
What Content Engineering Looks Like in Practice
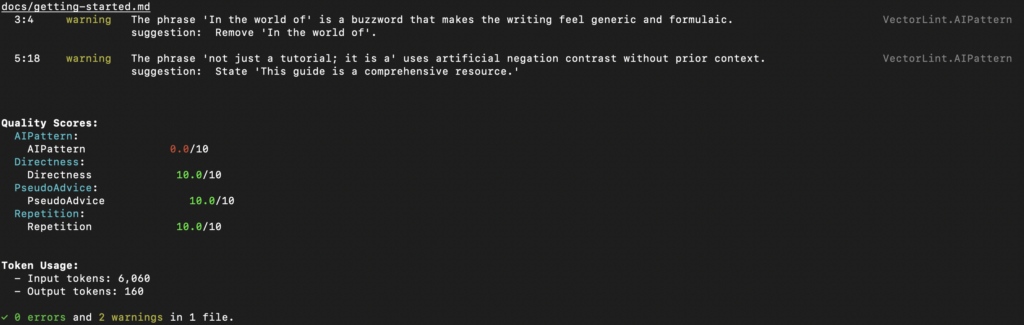
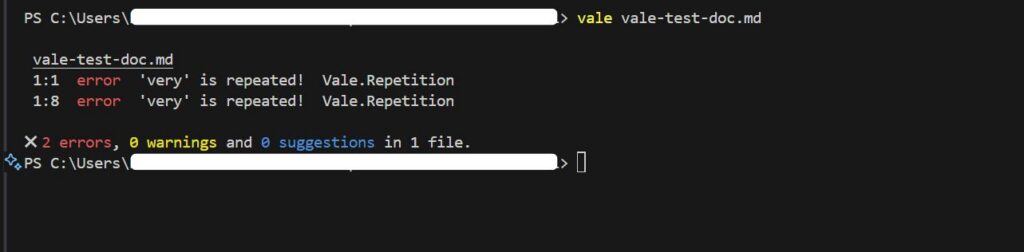
Whatever happens repeatedly in your editorial workflow is a candidate for automating away in a content system. It could be fixing broken links, handling drift, or fixing terminology inconsistencies.
For instance, if your docs live in the codebase, you can detect documentation drift by using a code review tool that can inspect pull requests for changed features and flag affected content for review. Tools such as Qodo and CodeRabbit does this quite well. If your docs live outside the repository, however, you would need to build a system that monitors releases or change logs, cross-references them with the content, and surfaces outdated pages.
Surfacing outdated pages could then automatically create a GitHub issue or a Slack notification to update the team.
AI can reduce manual work, but it shouldn’t make decisions for you. An agent can read and identify the sections that need changes, suggest revisions, and draft a first pass, but a human should still make the final decision to publish.
Although AI workflows can speed up work, a human still needs to remain accountable.
How Content Engineering Supports Developer Marketing
Content engineering supports developer marketing by helping you decide what to publish, write it, review it, and keep it consistent as your product changes.
You can build a repeatable workflow with a topic backlog, a brief template, a source-gathering step, quality checks, and a publishing process to bring in users, create search entry points, and explain your product well enough to earn trust.
This is how we built our demand generation workflow. We use AI for topic research and prioritization, while a human (just me for now) signs off on what to write, and briefs before handing it off to an agent who writes the first draft.
After that, the draft goes through automated quality checks, the agent revises until it meets our quality benchmark, and the human gives the final review. This setup enables one person to keep content moving while also handling software engineering work.
It could also be an event-driven system.
A feature launch can trigger an event that creates a content backlog, generates a brief from the changelog and source docs, drafts a tutorial or comparison post, and then runs checks for claims, terminology, and links before human review.
Whatever workflow is implemented, it must make content creation faster without sacrificing quality.
Benefits of Adopting Content Engineering Practices
Implementing a content system reduces content drift and maintains a good developer experience.
A content system also enforces consistency, making it easier for AI systems to trust and cite. Consistent, technically grounded content gives AI systems an unambiguous representation to work from, improving search visibility.
It also ensures that content quality doesn’t slip as you scale volume. Enforcing quality checks at the writing and submission stages helps you expand your topical coverage while keeping every piece aligned with the same standards.
Building a content system is also cost-effective. Not only does it reduce the workload on already overloaded technical writers or engineers, but it also enables you to scale production without a proportional increase in effort and resources.
Snyk was able to scale its developer marketing strategy by adopting content engineering practices, scaling its developer content production, and driving hundreds of thousands of additional web sessions
In-House vs Outsourcing Content Engineering
You could hire a content engineer to build your content system, or have an in-house technical writer fill the role.
Building a content system is ongoing work, though. The content engineer builds workflows, connects product development to content systems, adds quality gates, sets up knowledge bases, and improves the AI-assisted components when new tasks break the system. AI outputs aren’t deterministic, so the workflow needs ongoing calibration against your quality standards.
Technical writers already juggle documentation, reviews, and contributor support. Adding content engineering to their tasks forces them to context-switch between writing and systems work, which can lead to more content debt or an inefficient system.
At TinyRocket, we build content systems for developer tool companies when your team doesn’t have the capacity to take it on without diverting from the roadmap. We connect pull requests, releases, and change logs to your content inventory, route updates to the right owner, and set up quality-gated production workflows that keep documentation and marketing content aligned with product development.
Book a free workflow audit for an analysis of your editorial process to see where you could automate or apply AI to keep your docs aligned or produce more developer content without sacrificing quality.